很久没有写seo类的文章,我清晰的记得我写过文章已不干seo,但是形势所逼,不得不依靠百度存活,所以又回到了SEO的怀抱,但是此刻的我已经不是前两年的我。
今天我将证明一个推断,如果推断是对的,那么这篇文章就是个大家对于搜索引擎原理的认识一个推进器。
废话不多说了,前几个我上线了一个paperfree论文查重网站(www.qcool.cn),与此同时我研究了下用户搜索习惯移动端对于某些长尾词还是有需求的,况且目前移动化的脚步也越来越快,所以也做了个移动站(m.qcool.cn),PC与移动站内其实都没有问题,但是已经一个月过去了,PC的站内还是不收录,之前收录了几个又吐回去了:
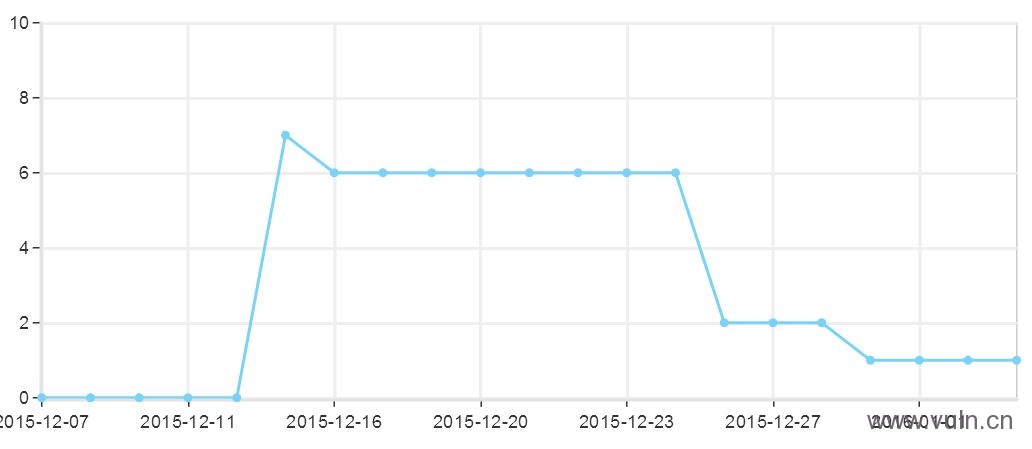
所以这一定是某方面有问题的,之前想了很多,可能是我新站外链太猛,友链权重过高,但是这么久了仍然是这个节奏,所以我在站长平台反馈了下,得到的回复我惊呆了:
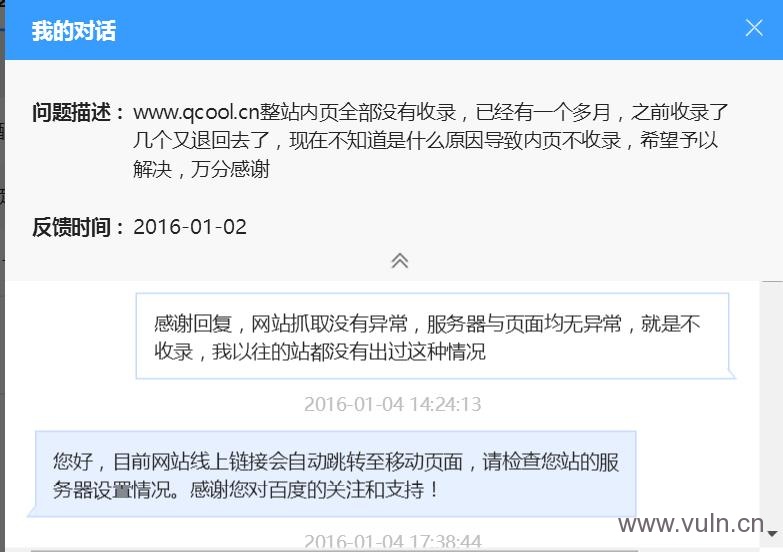 纳尼?pc与移动跳转我测试了很多,站长平台也抓取测试了,根本不存在问题。一开始我是拒绝相信的,但是后来想一想我还是相信了。
纳尼?pc与移动跳转我测试了很多,站长平台也抓取测试了,根本不存在问题。一开始我是拒绝相信的,但是后来想一想我还是相信了。
问题出在哪?
首先我的跳转代码是这样的,放在body下第一位:
<script>
if(navigator.platform.indexOf('Win32')!=-1){}
else{window.location.href="http://m.qcool.cn"+window.location.pathname;}
</script>
原理就是如果客户端不是windows的操作系统则跳转到移动站:m.qcool.cn对应的url,乍看上去没什么问题,也没有什么特殊情况。
而且我在站长平台也抓取了下:
 抓取诊断的结果也是没有问题的,并没有跳转到移动页面。
抓取诊断的结果也是没有问题的,并没有跳转到移动页面。
有的朋友可能会想到,百度蜘蛛并不是windows系统,会跳转的,但是我的跳转js是在body中,并不是在head中,蜘蛛不会立即识别到跳转,而且众所周知蜘蛛是不识别js的。
我的推测应该没有错
百度蜘蛛实际抓取与站长工具抓取诊断应该是一致的,从上往下抓取,head中没有跳转信息,不会跳转,蜘蛛抓取的源码的确就是pc页的源码。
但是我想到了一点,百度是如何识别作弊的?
如果我凭css和html把一个黑链定位到页面之外,百度又是怎么综合多个css就能判断这个元素是隐藏的?
如果我用js来输出一个DOM呢?百度不是不抓取js吗?怎么识别js的结果?
百度又是怎么凭借页面的源码来识别页面的工整性?
我得到的结论是,百度抓取了页面源码,一定会对其渲染,重现页面的前端样式。
如果是这样那么就很简单了,百度渲染页面的系统一定不会是windows,因为负荷太大,渲染过程页面的所有js,css,html等等都会生效来组成页面,那么我的js跳转识别也会生效,自然就在百度处理数据的过程中产生了跳转,所以用户在前端使用过程没有任何问题,百度识别却出了问题。
这就是为什么百度给我的回复却是跳转的。
这就是为什么我们看到的百度快照是前端页面,而不是页面源码。
如何证明?
我现在已经临时删除了跳转JS,看看收录是否正常,结果如何我会及时更新。
当天状态更新跟踪报道
当天内页立马陆续放出来了:

结论如何想必大家心里都有数了。
















 云悉指纹
云悉指纹